Instruct Fine-Tuning Mistral 7B with PEFT: A Cookbook


Large language models have swept through academia and industry alike in the last 2 years. Close-source chat and general-purpose language models such as ChatGPT, GPT-4 and Claude have quickly been rivaled by open source alternatives such as Llama, Llama 2, Falcon and many others.
However, it is worth noting that all of these models are massive with billions of parameters and whether it is economically worth it to deploy such models is up to debate. In fact, fine-tuning and deploying LLMs takes considerable engineering effort. This is why we are currently seeing a shift towards smaller models with new-comers such as Mistral 7B by Mistral AI and Zephyr 7B by Hugging Face with the latter outperforming Llama-2-70B variant.
In this blog post, we'll focus on Mistral 7B and learn how to fine-tune it efficiently on a custom dataset for a domain specific instruction-like task. We'll also talk about important concepts such as parameter efficient fine-tuning (PEFT) and different training strategies such as DPO. Finally, we will show how to perform quantization to downsize and speed up your model for deployment.
Table of contents
Introduction
What is a base language model and how is it different from a chat model or an instruction-based model? Let's break it down.
Models such as Llama 2 variants and Mistral 7B are generally first pre-trained on massive text datasets in a self-supervised manner with a generalizable training objective such as text completion. Self-supervised learning means the model takes a whole sequence of text and generates its own input and output. For example, models trained with the text completion objective take whole chunks of text samples, internally mask the text and try to predict the masked part given the preceding or context text depending on the learning objective. Once trained, this model serves as a general purpose base model that can perform a core task (e.g. masked word completion, next word prediction, etc.) but can also be fine-tuned for specific tasks such as chat or instruction-based question answering. Users can also train small models from scratch on top of the base model for other common NLP tasks such as named entity recognition or text classification but that's a topic for another blog post :)
Mistral and a Brief Guide to LLMs
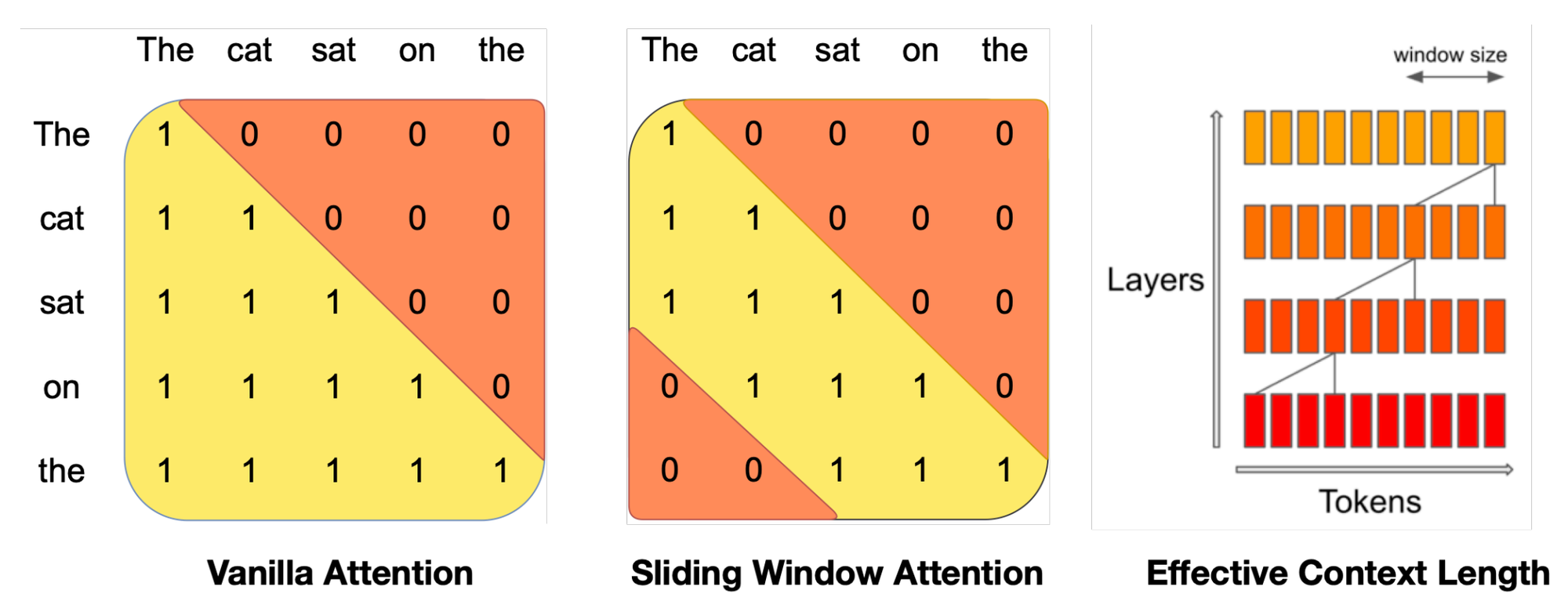
Let's briefly talk about Mistral 7B's architecture. Mistral is a transformer-based model that closely resembles Llama with a few changes. Namely, it leverages grouped-query attention (GQA) for faster inference, coupled with sliding window attention (SWA) to effectively handle sequences of arbitrary length with a reduced inference cost.
Dataset Schema
As explained in the introduction, models like Llama and Mistral 7B are trained with a text completion objective where the input is a partially masked piece of text and the target output is the completion. In order to fine-tune the base model to create chat or instruct models, we need to mimic this structure but also give the text a bit of structure such that it's easy to prompt the model and parse answers.
Let's give an example. Say we would like to fine-tune Mistral 7B to answer questions given a context and our dataset consists of input, context and output triplets:
dataset = [{"input": "Is it wrong to lie?", "context": "It's a white lie that doesn't hurt anyone and makes the other person happy.", "output": "Under these circumstances, it is not advisable but reasonable to lie."}, {...}]
We can convert this dataset to a format consumable by Mistral 7B by generating a structured text input:
#### Input:
Is it wrong to lie?
#### Context:
It's a white lie that doesn't hurt anyone and makes the other person happy.
#### Output:
Under these circumstances, it is not advisable but reasonable to lie.
Note that we merely formatted the dataset to create a single text blob for each sample. If we were working on a task that didn't require a context, we could have eliminated the context header completely. The headers and blank lines are also completely arbitrary choices that make it easier for the model to learn a structure. Mistral 7B will generate masked examples for text completion during fine-tuning. Once fine-tuned, we can simply prompt the model with an incomplete text and retrieve the completion as the answer:
#### Input:
Is it wrong to lie?
#### Context:
It's a white lie that doesn't hurt anyone and makes the other person happy.
#### Output:
Parameter Efficient vs Vanilla Fine-tuning
PEFT stands for parameter efficient fine-tuning and encompasses many methods, including LoRA. Before diving into PEFT, let's talk about vanilla fine tuning first. Deep learning models are mathematical functions with large language models often having billions of learned parameters. Vanilla fine-tuning simply means tuning all parameters of the base model when further training it on a new dataset. Unfortunately, this can be very costly and time-consuming even with a small dataset as vanilla fine-tuning requires computing and storing the gradients of billions of parameters. The PEFT paradigm aims to make fine-tuning more efficient by identifying a small number of target parameters to be tuned while keeping the rest of the learned parameters frozen / unchanged.
In this tutorial, we will be using the peft library to fine-tune Mistral 7B with LoRA. Keep in mind that PEFT methods are not perfect and are more prone to catastrophic forgetting and drifting. This is because nudging some of the parameters too much while keeping other parameters frozen deregularizes the latent space. Hence, it is recommended to use smaller learning rates with PEFT compared to vanilla fine-tuning.
Learning Strategies
We talked about basic learning objectives for pre-training, and the differences between vanilla and parameter efficient fine-tuning, but we haven't covered how LLMs are trained to perform specific tasks such as instruction following or chat. Once again, auto-regressive text generative models such as Mistral 7B are pre-trained with the objective of next word prediction without any labelled dataset. If we have a large domain-specific text dataset (e.g. medical, code), we can simply choose to pre-train the model from scratch or resume pre-training from the checkpoint using the same next word prediction objective and a self-supervised learning schema in order to generalize to the chosen domain.
However, the pre-trained LLMs already capture a lot of knowledge we can capitalize on and it often makes more sense to customize the pre-trained model more efficiently with a small labeled dataset. In this tutorial, we will use the TRL library, which provides a set of tools to train and fine-tune transformer language models with Reinforcement Learning. TRL implements a lot of RL training frameworks for us, including Supervised Fine-tuning (SFT), Reward Modeling (RM), Proximal Policy Optimization (PPO), Direct Preference Optimization (DPO) and more. Let's do a brief introduction to these training strategies:
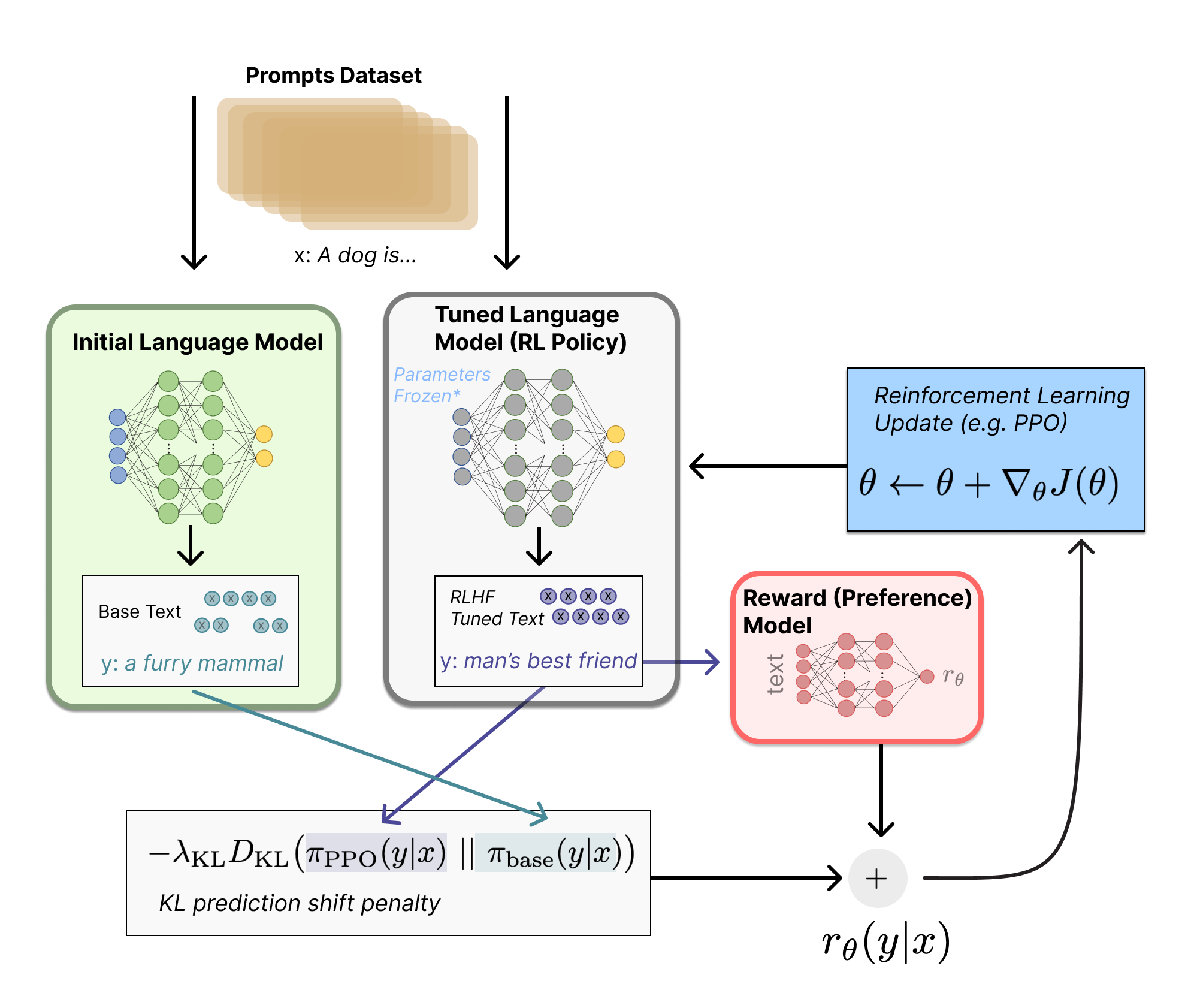
Supervised Fine-Tuning (SFT):
LLMs such as Llama and Mistral 7B are trained in a self-supervised fashion with the next word prediction objective. Supervised fine-tuning simply enables fine-tuning a pre-trained LLM on labeled (input, completion) text pairs such as our style-instruct dataset. In reinforcement learning (RL), this means further training of an initial policy (the model that determines actions) using the additional reward signals from this labeled dataset to encourage behavior that achieves a specific goal or task.
Proximal Policy Optimization (PPO):
PPO is a policy gradient algorithm for directly optimizing policies. Whereas supervised fine-tuning uses additional labeled data or reward signals that directly indicate the desired behavior, PPO optimizes the policy to maximize reward through taking actions in the environment, without any supervised labels or feedback. Instead, it uses the reward signal from the environment as its "training signal". It slowly improves the policy to favor actions that lead to higher long-term reward.
The reward signal in PPO can come from a handcrafted rule (e.g. not including curse words), a metric (e.g. text classification output) or from preference data using a Reward Model. PPO is flexible and enables active learning from user interactions. In practice, it is common to first perform supervised fine-tuning and then resort to PPO to achieve optimal results.
Direct Preference Optimization (DPO):
DPO takes a different approach to policy optimization than PPO. Instead of using numeric scalar rewards, whether it is a handcrafted metric or a text classification score, DPO directly compares entire trajectories generated by policies via human preferences. Humans provide qualitative relative judgments, indicating which trajectory is better and DPO optimizes the policy based on these preferences through gradient descent - improving it to generate trajectories more aligned with human preferences.
A key advantage of DPO is that it removes the challenge of defining the right numeric rewards and shaping rewards. Humans simply provide qualitative feedback to directly mold behavior as desired. However, PPO has advantages in terms of ease of automation and sample efficiency as users have to provide high-quality pairs of comparative preferences for DPO.
For more information about these methods, see this excellent blog post on Reinforcement Learning from Human Feedback.
Quantization
Once we fine-tune an LLM for a target task, deploying and running that model for inference can still be challenging due to its size and computational demands. Quantization is a model compression method that involves converting high precision floating point model parameters (typically 32 or 16-bit) into smaller integer equivalents (e.g. 8 bit or even lower bit width). This makes the model much smaller in memory and faster to run, especially on specialized hardware.
There are two main ways of performing quantization:
- Post-training quantization: the trained model parameters are mapped to a reduced precision after training is complete. The parameters to be converted to a lower precision are typically selected via an analysis of the distribution. No further fine-tuning is done.
- Quantization-aware training: the model is trained or fine-tuned with a fake quantization process in the loop, essentially forcing the model to be robust to quantization directly in how it learns. Actual quantized weights/activations are used to fine-tune the model.
Quantization-aware training leads to more reliable and better performing quantized models, but takes longer to train. Post-training quantization is simpler and faster.
How to Fine-tune Mistral 7B
We covered all the basics and are now ready to jump into coding. We will be using Hugging Face's datasets, transformers, trl, accelerate, peft and bitsandbytes libraries.
In this tutorial, we will be fine-tuning Mistral 7B using PEFT, Supervised Fine-Tuning (SFT), and 4-bit quantization. For a full list of the dependencies and the code, you can directly head over to our tutorial repository.
Dataset & Preprocessing
We will create an instruct-based model by fine-tuning Mistral 7B v0.1 on a style recommendation dataset - neuralwork/fashion-style-instruct. This dataset contains 3,193 text triplets that consists of an input describing the user's body type and personal style, a context describing the type of event (e.g. concert, date, business meeting), and a completion. The completion is what we want the LLM to generate and contains 5 unique outfit combinations based on the user's body type and personal style preferences.
from datasets import load_dataset
# download dataset
dataset = load_dataset("neuralwork/style-instruct")
print(dataset)
# print a sample triplet
print(dataset["train"][0])
Next, we need to create a formatting function that takes in a dataset row and outputs structured text. Note that since we will use the SFTTrainer class, we will need to input both the original labeled dataset containing the triplets and the formatting function. Let's go ahead and create the formatting function:
def format_instruction(sample):
return f"""You are a personal stylist recommending fashion advice and clothing combinations. Use the self body and style description below, combined with the event described in the context to generate 5 self-contained and complete outfit combinations.
### Input:
{sample["input"]}
### Context:
{sample["context"]}
### Response:
{sample["completion"]}
"""
Notice we added an extra instruction to the beginning of the text describing the role of the model as a personal stylist. This chunk is what is known as a system prompt and can be changed or can take on different values based on the end task. Since our goal is to create a style bot that outputs outfit recommendations, we will keep the system prompt fixed. Our goal is to allow users to input their prompts (ìnput) and select from a list of events (context`). Let's format a sample from our dataset.
sample = dataset["train"][0]
print(format_instruction(sample))
Fine-Tuning with PEFT and SFT
Time to fine-tune Mistral 7B! Our goal is to fine-tune and deploy our stylist model efficiently. To this end, we will start by creating a BitsAndBytesConfig to perform 4-bit post-training quantization on the base Mistral 7B model and perform quantization-aware fine-tuning.
from transformers import BitsAndBytesConfig
# BitsAndBytesConfig to quantize the model int-4 config
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
Next, let's load the pre-trained Mistral 7B v0.1 model and its tokenizer. The tokenizer is simply a preprocessor that converts raw text input into a fixed-length numerical format that can be consumed by the model, where each word and punctuation mark is assigned a unique id.
from transformers import AutoTokenizer, AutoModelForCausalLM
# base model id to fine-tune
model_id = "mistralai/Mistral-7B-v0.1"
# load model
model = AutoModelForCausalLM.from_pretrained(
model_id,
quantization_config=bnb_config,
use_cache=False,
device_map="auto"
)
model.config.pretraining_tp = 1
# load tokenizer, pad short samples with end of sentence token
tokenizer = AutoTokenizer.from_pretrained(model_id)
tokenizer.pad_token = tokenizer.eos_token
We have successfully loaded and quantized our base Mistral 7B model. As covered in the PEFT section, it is often not computationally feasible to fine-tune all parameters of such large-scale models. Hence, we will be using LoRA and fine-tune only a small subset of the model parameters. The next thing we need to do is to create PEFT training configuration. Luckily for us, the peft library has a lot of handy functions that helps prepare the model for both parameter-efficient and quantized t
from peft import LoraConfig
# LoRA config based on QLoRA paper
peft_config = LoraConfig(
r=32,
lora_alpha=64,
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
"lm_head",
],
bias="none",
lora_dropout=0.05,
task_type="CAUSAL_LM",
)
Note that we select the subset of parameters to be fine-tuned based on best practices and previous work on the topic. For more information on LoRA works, refer to the original paper and peft docs. Let's go ahead and prepare the base model for quantization-aware fine-tuning with LoRA.
from peft import prepare_model_for_kbit_training, get_peft_model
# prepare model for training
model = prepare_model_for_kbit_training(model)
model = get_peft_model(model, peft_config)
We fully prepared our model for efficient fine-tuning. If you want to see what percentage of the parameters we are fine-tuning, you can use the following utility function:
def print_trainable_parameters(model):
"""
Prints the number of trainable parameters in the model.
"""
trainable_params = 0
all_param = 0
for _, param in model.named_parameters():
all_param += param.numel()
if param.requires_grad:
trainable_params += param.numel()
print(f"trainable params: {trainable_params} || all params: {all_param} || trainable%: {100 * trainable_params / all_param}")
# get frozen vs trainable model param statistics
print_trainable_parameters(model)
We are now ready to create our trainer class. We will use the transformers and trl libraries to perform supervised fine-tuning with the neuralwork/ fashion-style-instruct dataset. The TrainingArguments class of transformers comes in especially useful as it encapsulates the training setup in a simplified way.
For this experiment, we will use a constant learning rate of 2e-4 and fine-tune Mistral 7B for 3 epochs. As we are performing PEFT, it is recommended to not exceed 5 epochs in order to avoid deregularizing the latent space and causing catastrophic forgetting. The trainer classes of transformers and trl also implement gradient checkpointing, which significantly reduces GPU memory cost during training at the cost of a small decrease in the training speed due to recomputing parts of the graph during back-propagation.
from trl import SFTTrainer
from transformers import TrainingArguments
model_args = TrainingArguments(
output_dir="mistral-7b-style",
num_train_epochs=3,
per_device_train_batch_size=4,
gradient_accumulation_steps=2,
gradient_checkpointing=True,
optim="paged_adamw_32bit",
logging_steps=10,
save_strategy="epoch",
learning_rate=2e-4,
bf16=True,
tf32=True,
max_grad_norm=0.3,
warmup_ratio=0.03,
lr_scheduler_type="constant",
disable_tqdm=False
)
# Supervised Fine-Tuning Trainer
trainer = SFTTrainer(
model=model,
train_dataset=dataset,
peft_config=peft_config,
max_seq_length=2048,
tokenizer=tokenizer,
packing=True,
formatting_func=format_instruction,
args=model_args,
)
# train
trainer.train()
And that's it. Fine-tuning Mistral 7B on this dataset takes about 4 hours on a single NVIDIA A40 GPU. Once the model is fine-tuned, we can save the model to a local folder or push it to Hugging Face Hub:
# save model to output_dir in TrainingArguments
trainer.save_model()
# login to HF hub
from huggingface_hub import login
login(<YOUR_HF_TOKEN>)
# push model and tokenizer to HF hub under your username
trainer.model.push_to_hub("mistral-7b-style")
tokenizer.push_to_hub("mistral-7b-style")
We have now pushed the fine-tuned model and tokenizer to the Hugging Face Hub. Keep in mind that we fine-tuned Mistral 7B with LoRA, which means that we only fine-tuned a small subset of the model parameters while keeping other parameters frozen. The push_to_hub method only uploads the LoRA parameters, which can be used to overwrite the corresponding parameters of the original base model.
Testing Fine-Tuned Model
Time to test our fine-tuned model. Let's see if we can get good style recommendations from Mistral. We will start by loading the pre-trained model and tokenizer. As mentioned in the previous section, only the LoRA parameters are uploaded to the Hub. Hence, we will need to import a special peft class called AutoPeftModelForCausalLM to load the LoRA parameters and merge them with the base Mistral 7B model.
from peft import AutoPeftModelForCausalLM
from transformers import AutoTokenizer
# fine-tuned model id
model_id = "neuralwork/mistral-7b-style-instruct"
# load base LLM model, LoRA params and tokenizer
model = AutoPeftModelForCausalLM.from_pretrained(
model_id,
low_cpu_mem_usage=True,
torch_dtype=torch.float16,
load_in_4bit=True,
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
Next, we need to select a random sample from the dataset. Note that the objective of our fine-tuned model is still text completion and we need to format the dataset samples in a way that allows us to generate the target output - sets of outfit recommendations. In order to do this, let's create a new formatting function and format a randomly selected dataset sample.
from random import randrange
def format_instruction(sample):
return f"""You are a personal stylist recommending fashion advice and clothing combinations. Use the self body and style description below, combined with the event described in the context to generate 5 self-contained and complete outfit combinations.
### Input:
{sample["input"]}
### Context:
{sample["context"]}
### Response:
"""
# select random sample
sample = dataset[randrange(len(dataset))]
# create prompt for inference
prompt = format_instruction(sample)
print(prompt)
We now have a text input that contains a system prompt, user prompt and a context describing the event the user wants to go to (e.g. business meeting, casual date). Let's go ahead and perform inference with our fine-tuned model.
import torch
device = "cuda" if torch.cuda.is_available() else "cpu"
# tokenize input text
input_ids = tokenizer(prompt, return_tensors="pt", truncation=True).input_ids.to(device)
# inference, 5 outfit combinations make up around 700-750 tokens
with torch.inference_mode():
outputs = model.generate(
input_ids=input_ids,
max_new_tokens=800,
do_sample=True,
top_p=0.9,
temperature=0.9
)
Inference with a quantized pre-trained model is easy but we are not done yet. The model outputs a list of token ids, which corresponds to the completed text. In order to retrieve the output combinations, we first need to convert the output token ids to human readable text and parse the completed part. We will use a small postprocessing utility function to decode the token ids and compare the generated output to the ground truth output in the dataset.
# decode token ids to text
outputs = outputs.detach().cpu().numpy()
outputs = tokenizer.batch_decode(outputs, skip_special_tokens=True)
# outputs is a list of length num_prompts
# parse the completed part
output = outputs[0][len(prompt):]
print(f"Instruction: \n{sample['input']}\n")
print(f"Context: \n{sample['context']}\n")
print(f"Ground truth: \n{sample['completion']}\n")
print(f"Generated output: \n{output}\n\n\n")
And that's it. You learned how to fine-tune and use Mistral 7B, along with the internals of peft and trl libraries. You can find the organized code for our tutorial in our GitHub repository, which includes a Gradio demo to play around with the fine-tuned model.
Conclusion
Open source large language models such as Mistral 7B have massive potential to automate many tasks across different industries. However, companies often need to fine-tune or train their own models to fit their needs. This requires not only an engineering know-how but also a basic understanding of how LLMs work and how they are trained. In this blog post, we talked about parameter efficient fine-tuning as well various learning and deployment strategies, and fine-tuned a personalized outfit recommendation bot.
We are continuously publishing blog posts with in-depth research reviews and cutting edge code tutorials. To stay up to date with the latest news in AI research, you can follow us on Twitter: @adirik, @neuralwork, and LinkedIn.



