A Survey on Image Generation and Generative Image Editing


The ability to generate and edit images using AI has evolved dramatically in the past few years. While diffusion models such as Stable Diffusion and Flux currently dominate the image generation landscape, recent hybrid architectures combining autoregressive and diffusion approaches have demonstrated comparable quality with significantly better computational efficiency. In this blog post, we'll explore the technical evolution of generative image editing and take a closer look at how different architectural paradigms shaped current capabilities - from early GAN, VAE and normalizing flow architectures through the diffusion revolution, and into today's hybrid approaches.
Table of Contents
- Early Foundations: VAEs, GANs, and First Steps
- The Diffusion Era
- Autoregressive and Hybrid Approaches
- Image Editing Paradigms
- Future Directions
Introduction
.](https://blog.neuralwork.ai/content/images/2024/12/timeline-of-text-to-image.png)
Image generative models evolved from early proof-of-concept architectures generating simple MNIST digits to today's state-of-the-art systems capable of photorealistic image generation and editing. The field gained momentum with Generative Adversarial Networks (GANs), which used adversarial training to achieve unprecedented image quality, particularly in domain-specific tasks. This was followed by advances in VAE-based approaches like VQ-VAE and normalizing flows, which focused on learning controllable latent representations at the cost of some image quality.
The field then saw two major shifts: first with diffusion models demonstrating stable training and high-quality outputs through iterative denoising, and more recently with hybrid approaches that combine autoregressive modeling with diffusion techniques to maintain quality while dramatically improving computational efficiency. Each architecture brought unique strengths - GANs excelled at image quality, VAEs provided controllable latent spaces, and diffusion models offered stability and strong conditioning capabilities grounded in language.
In this post, we'll explore this evolution, focusing on how each architecture contributed to our current capabilities, and analyze the trade-offs between different approaches to image editing and generation.
Early Foundations: GANs, VAEs and First Steps
The first big leap in modern image generation was achieved with Generative Adversarial Networks (GANs) in 2017, with a simple but highly effective idea. GAN proposed an adversarial training dynamic between two competing networks: a generator to generate synthetic images and a discriminator to distinguish between real and synthetic images. This strategy achieved primitive (by today's standards) but very promising results on domain restricted and low resolution datasets such as MNIST, TFD and CIFAR-10.
Early GANs struggled with training instability and mode collapse, but architectural innovations like DCGAN, Progressive Growing, and StyleGAN progressively overcame these limitations.

Parallel developments in Variational Autoencoders (VAEs) focused on learning compressed latent representations of images. By encoding images into a continuous latent space, VAEs enabled semantic manipulation through vector arithmetic - adding and subtracting features in the latent space would correspondingly modify the decoded image. While these approaches initially lagged behind GANs in image quality, they offered better control through explicit latent spaces. Later works like VQ-VAE, VQ-VAE-2, and normalizing flows like GLOW significantly improved output fidelity while maintaining controllability.
The Diffusion Era

Diffusion models marked a paradigm shift by framing generation as gradual denoising of random noise from a noised image. DDPM first proposed this approach in 2020 using a U-Net based denoiser architecture to reverse a fixed noising process. A major efficiency breakthrough came from Latent Diffusion Models, which applied diffusion in the latent space of a pre-trained autoencoder (similar to VQ-VAE) instead of the image space, dramatically reducing computational requirements.
Another major breakthrough was the leap from domain restricted image generation via classifier guidance to non-domain restricted text-to-image generation with classifier-free guidance, which enabled many works such as GLIDE, Stable Diffusion and DALL-E 2.
Sampling efficiency also improved through methods like DPM-Solver, while Consistency models demonstrated single-step generation. More recently, transformer-based architectures have begun replacing U-Net based denoisers in diffusion models. DiT showed that transformers could match or exceed U-Net performance. This led to even more efficient models like PixArt-α, Flux and SANA that maintain high quality while reducing the number of denoising steps required.

Autoregressive and Hybrid Architectures
Autoregressive models proposed a fundamentally different approach by treating images as sequences to be generated one element at a time, similar to how language models generate text word by word. Early models like PixelCNN generated images pixel by pixel, while later approaches like VQGAN first compressed images into a smaller set of learned discrete tokens - think of these as visual "words" that represent common image patterns. This shift from pixels to learned tokens enabled the use of transformer architectures that had revolutionized NLP, representing a significant step in bridging language and vision.
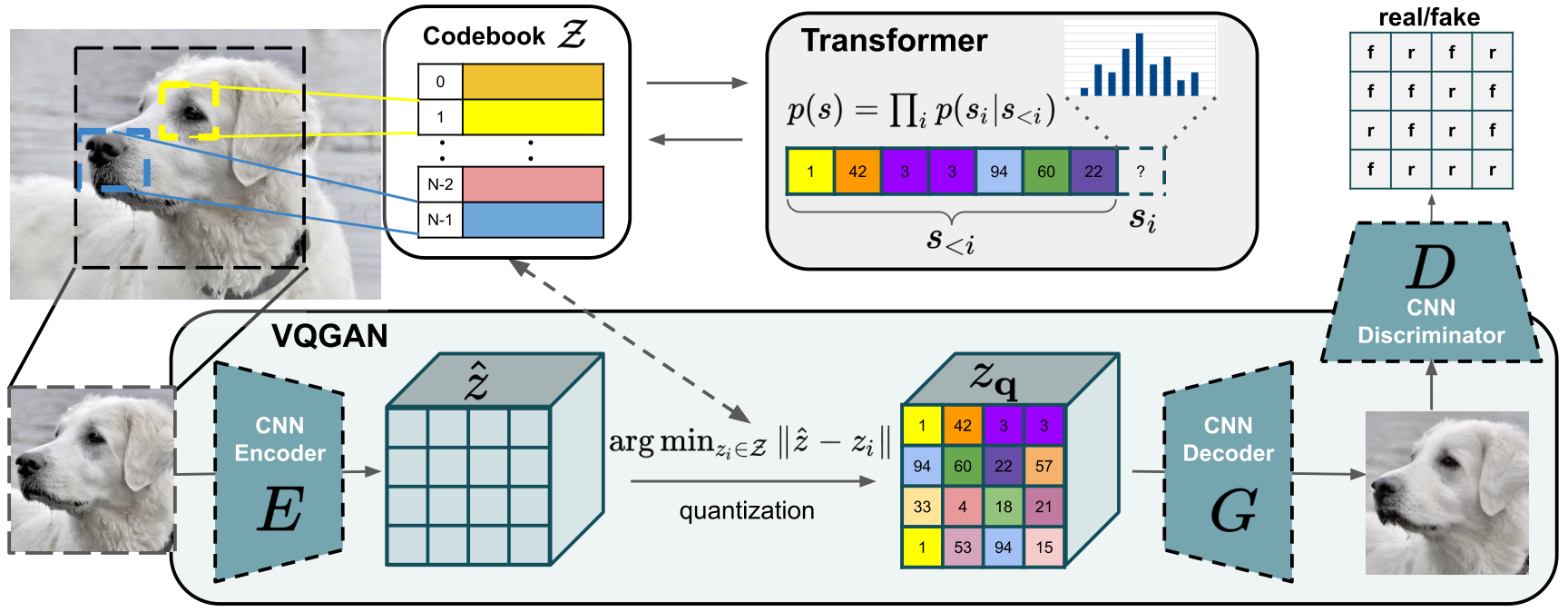
The initial challenges were clear: generating one element at a time was slow, and the resolution of generated images was limited. Several key innovations transformed the landscape. MaskGIT introduced parallel decoding strategies that could predict multiple tokens simultaneously. CogView and its successor demonstrated the potential of large-scale autoregressive transformers, while Make-A-Scene enhanced composition control through scene layouts. Perhaps most significantly, DALL-E showed that these models could generate complex images from text descriptions by leveraging hierarchical tokenization schemes that capture both broad structure and fine details.
Most recently, hybrid approaches like HART have tackled the fundamental trade-offs by using two types of representations: discrete tokens (like visual words) capture the overall structure, while continuous values (like a smooth gradient of features) handle fine details. This combination maintains the benefits of step-by-step generation while matching the quality of diffusion models at a fraction of the computational cost and inference time.

Image Editing Paradigms
The evolution of image generative models has enabled several distinct approaches to image editing. Despite the signigicant advancements in image generation, a key challenge across all paradigms remains balancing precise control with overall edit quality. Before examining different approaches for image editing, let's first talk about what image editing entails, and how it differs from controllable generation and personalization.
Editing vs Control vs Personalization
Image Editing refers to making targeted changes to specific aspects of an image while preserving others. For example, changing a person's hair color while maintaining their identity, or modifying the style of a building while keeping its structure intact.
Controllable Generation uses auxiliary signals to guide the generation process. Recent advances like ControlNet and T2I-Adapter have made this particularly effective by learning modality-specific conditioning:
- Structural guidance through sketches, edges, or segmentation masks
- Compositional control via depth maps or pose estimation
- Style control through reference images
- Domain adaptation through cross-domain mapping
These models use different approaches to inject control signals into the generation process. ControlNet adds parallel conditioning layers to a pretrained diffusion model, while T2I-Adapter introduces lightweight adaptation modules that can be efficiently combined. More recently, approaches like Arc2Face have demonstrated effective identity-conditioned generation by using face recognition features as control signals.
Personalization focuses on teaching models to understand and preserve specific concepts:
- Textual Inversion learns to represent concepts as textual embeddings within the embedding space of a frozen text-to-image model
- DreamBooth fine-tunes the model to learn new tokens or "words" that represent the concept
- Custom embedding spaces for identity preservation
These capabilities often complement each other in practice. For instance, editing a person's appearance might require both personalization (to preserve their identity) and controlled generation (to guide the specific changes).

Training-based Methods
Training-based methods optimize models for specific editing tasks through additional training. In instruction-guided editing, InstructPix2Pix learns from paired before/after images with text instructions, while Composer enables composition-preserving edits through language. SINE focuses on structure-preserving image editing. Cross-modal approaches like BLIP-Diffusion leverage vision-language alignment, and ImageBrush enables region-aware editing through language. Another set of approaches for editing via model training leverages text-to-image models and equates the image editing task to the text-guided inpainting task. This entails simply fine tuning pre-trained text-to-image models with a simple fill-in-the-mask objective using masked and unmasked image pairs.
The main advantage of much methods is learning complex, semantically meaningful edits, though at the cost of requiring training data and compute for each new capability.
Optimization-based Methods
Optimization-based approaches treat editing as a search problem in the model's latent space. Rather than learning new behaviors, these methods find optimal paths in existing latent spaces to achieve desired edits. Key techniques include:
- Style direction discovery through latent space analysis
- Semantic factorization for attribute manipulation
- Energy-based optimization with perceptual losses
- Text-guided latent space navigation

These methods are particularly effective for attribute-level editing (e.g., changing age, expression, or style) as they can leverage the natural organization of the latent space. However, they can be computationally intensive and may struggle with complex semantic changes that require understanding of high-level concepts. Early works on image editing operated within the latent space of pretrained GANs, with works such as GANSpace, HyperStyle and InterfaceGAN proposing unsupervised and supervised methods to find global and semantically disentangled editing directions respectively. Later on, works such as StyleCLIP and StyleMC took these ideas further by using CLIP to eliminate the need for labeled images and find text-guided style directions. These methods excel at attribute-level editing but can be computationally intensive. It is also worth noting that the architecture and inference speed of GANs made them ideal candidates for optimization-based methods, whereas they are not practical for iterative generative models such as diffusion models due to their noise removal process and higher inference times. Another advantage of GAN's inference speed is it made it relatively easy to invert real images either via optimization or through training a separate inversion model (e.g. HyperStyle).
Inference-time Methods
Inference-time image editing methods try to steer the generation towards a target direction during the generation process itself. Such methods have gained popularity with the rise of diffusion and hybrid models for reasons we just talked about. The key advantage of inference-time methods is their flexibility - they can perform edits without training or expensive optimization. Recent hybrid architectures have made these methods particularly efficient by combining the speed of autoregressive models with the quality of diffusion approaches.

Such approaches can be categorized as follows:
-
Cross-attention control in diffusion models
- Manipulating attention maps to guide generation
- Region-based attention control for localized edits
- Multi-concept attention control
-
Prompt-based editing through classifier-free guidance
- Negative and positive prompting
- Composition through prompt weighting
- Structural guidance through text
- Pre-computed textual directions
Attention-based methods like Prompt-to-Prompt manipulate cross-attention for local edits, Direct Inversion and Null-text Inversion enable better preservation of source images, and Attend-and-Excite provides enhanced object control. In the prompt-based editing through classifier-free guidance category, Imagic enables subject-driven editing, MasaCTRL provides fine-grained compositional control, DiffEdit offers mask-free editing capabilities and LEDITS proposes using textual style directions to edit inverted images. Other works such as [LEDITS++] propose hybrid approaches that combine textual manipulations with attention mask-based semantic groundings to preserve irrelevant parts of the image while making targeted edits.
Future Directions
While image generative models have come a long way, they are still very limited in understanding the visual world, with even the SOTA text-to-image models having very poor counting and spatial reasoning capabilities. As we look forward, several trends are shaping the future of generative image editing:
- Faster and more efficient image generative architectures
- Better semantic understanding in image generation enabling better and more precise image editing methods
- Improved preservation of identity and structure during editing
- More, fine-grained text-guided image editing and inpainting methods
- Real-time editing capabilities
Conclusion
Image generation and editing is a fast evolving field with different architectural innovations have enabling different and increasingly sophisticated editing capabilities. While each architectural paradigm brings its own strengths and advantages, precise, disentangled and non-target attribute preserving edits of real and generated images is still an active research problem. As the field continues to evolve, we're likely to see more unified architectures that simulatenously enable generation and editing.
If you enjoyed reading this blog, we are continuously publishing blog posts with in-depth research reviews and cutting-edge code tutorials. To stay up to date with the latest news in AI research, you can follow us on Twitter: @adirik, @neuralwork, and LinkedIn.



